How BeanHub works part2, large-scale auditable Git repository system based on container layers
In the previous article, How BeanHub works part1, contains the danger of processing Beancount data with sandbox, we introduced how we use containers to process user-uploaded data securely. Today, we would like to introduce how we use a layer-based file system to facilitate a large-scale auditable Git repository system.
Look inside the .git folder
Have you ever wondered what’s inside the .git folder, what happens when you commit, and what happens when you perform a Git push?
The Git repository folder is pretty straightforward.
When you run the init command in an empty folder like this:
git init
And then
ls -al .git
You will see files and folders like this:
drwxr-xr-x 7 fangpen users 4096 Jun 26 03:32 .
drwxr-xr-x 3 fangpen users 4096 Jun 26 03:32 ..
-rw-r--r-- 1 fangpen users 23 Jun 26 03:32 HEAD
drwxr-xr-x 2 fangpen users 4096 Jun 26 03:32 branches
-rw-r--r-- 1 fangpen users 92 Jun 26 03:32 config
-rw-r--r-- 1 fangpen users 73 Jun 26 03:32 description
drwxr-xr-x 2 fangpen users 4096 Jun 26 03:32 hooks
drwxr-xr-x 2 fangpen users 4096 Jun 26 03:32 info
drwxr-xr-x 4 fangpen users 4096 Jun 26 03:32 objects
drwxr-xr-x 4 fangpen users 4096 Jun 26 03:32 refs
When you commit, different kinds of Git object files are created and put inside the objects folder. These include blob, tree, and commit objects. Each file has its unique ID. Usually, ID is the sha1 hash value of the object file. For example, now let’s make a commit and see what file it generated for us:
echo 'hello' > README.md
git add README.md
git commit -m "Initialize repo"
And then we check the git log by running git log:
commit ae4b007a21b69737806086be7887e4b141fe61f3 (HEAD -> master)
Author: Fang-Pen Lin <hello@fangpenlin.com>
Date: Wed Jun 26 03:43:02 2024 +0000
Initialize repo
You see, the commit id ae4b007a21b69737806086be7887e4b141fe61f3 is actually the sha1 value of the commit file object.
Your ID of the first commit will certainly be different from mine because your author name and timestamp will differ from mine, and thus, the sha1 hash value will be different.
Let’s see what’s inside the objects folder now by running:
tree .git/objects
And here you will see
.git/objects
├── 85
│ └── 3694aae8816094a0d875fee7ea26278dbf5d0f
├── ae
│ └── 4b007a21b69737806086be7887e4b141fe61f3
├── ce
│ └── 013625030ba8dba906f756967f9e9ca394464a
├── info
└── pack
As you can see, the 4b007a21b69737806086be7887e4b141fe61f3 file object in the ae folder is actually the commit object ae4b007a21b69737806086be7887e4b141fe61f3.
To speed up the search for files, Git puts object files into two-character prefix folders.
You can run it to view the content of the commit Git object:
git cat-file commit ae4b007a21b69737806086be7887e4b141fe61f3
And you should see this:
tree 853694aae8816094a0d875fee7ea26278dbf5d0f
author Fang-Pen Lin <hello@fangpenlin.com> 1719373382 +0000
committer Fang-Pen Lin <hello@fangpenlin.com> 1719373382 +0000
Initialize repo
As you can see, it’s pointing to a tree object 853694aae8816094a0d875fee7ea26278dbf5d0f.
that file contains the snapshot of the file tree structure of your commit.
You can also run the following command to see the content of the tree object like this:
git cat-file tree 853694aae8816094a0d875fee7ea26278dbf5d0f
We don’t want to discuss too many details about how Git works here.
If you are interested in it, I recommend you read Pro Git to learn more.
But now you get the idea: when you make a commit with Git, it actually creates a bunch of files and inserts them into the .git/objects folder; it also updates other files, such as your branch ref, making it point to the new commit.
What about push, pull, or clone, you ask? A protocol allows two Git repositories to exchange what each other has and decide what to push over or pull from the other repository. The missing files in the objects folder will be sent over the wire, and eventually, both repositories will have the same necessary objects for the desired branch. There are some exceptions, such as shadow clones, but that’s outside of our topic today.
The problem of hosting a Git repository
A hosted Git repository on the server is fundamentally the same as your .git folder in your local clone because Git is a distributed version control system, and they designed it to make every repository equal.
So, to host a Git repository, you only need to keep the content of the .git folder and provide the supported protocols for other Git repositories to communicate with it and exchange content.
When hosting only your project on a server, things are easy.
But when you are hosting for a large-scale multi-tenant use-case, things become trickier.
When we built BeanHub, we faced the following challenges when designing the Git repository hosting system.
Availability problem
The first challenge we face is the availability issue. The Git repository folder content is a stateful file folder. Certainly, we can easily host them in a Kubernetes volume and call it a day, but what if the pod or the node hosting that volume goes down, and the user needs to access the repository? We thought about using volume replica technologies to sync the volume across machines so that we have more than one copy. In that way, even if one machine goes down, another machine is still running with the same repository content.
However, by doing so, we must ensure that only the machine writes to the folder. Otherwise, we may have a consistency issue. And even if we can do that, we may still encounter other problems.
Durability problem
Durability is also critical to us because we don’t want our users to experience data loss. Hosting the Git repository in a volume could be potentially dangerous, as the volume could be accidentally deleted or lost due to a data center incident. While such events are rare, they did happen in the past, such as when the Google Cloud Platform reportedly wiped out customers’ data by mistake or a fire incident in the data center wiped out data for some customers. To avoid situations like these, we need to find a way to make our repository as durable as possible.
Scalability problem
While this may sound a bit crazy, it’s a service for hosting Beancount accounting books, and we think it should work like GitHub. It should still work even if thousands of people clone the same repository. We have free public repositories for non-profits or other public interest organizations to host their accounting books with BeanHub. With volume replication, you can only have up to a certain level of replicas, say two or three. But say when you have thousands of people cloning or reading the same repository, you must serve the traffic with only the machines with access to those volumes, and they could be overwhelmed. That’s another reason volume sync may not be the best idea.
Keep an audit track of what’s changed
Yet another challenge we faced when designing the system was considering the integrity of the repository folder and keeping an audit trail of what’s changed over time. After all, it’s hosting accounting books. If someone force-pushed a branch and rewrote the Git history, we want to be able to tell who did it and what’s changed in the Git repository. Other than force-push, we also need to think about the possibility when one finds an unexpected way to overwrite the content of the Git folder or there’s a bug in the Git runtime that results in a corrupted Git repository folder. In those cases, we should know when and how it happened and need a way to revert it to the working state.
Atomic operations
Most Git operations are atomic by design. For example, when one makes a git push, the newly added content will live in a “quarantine” folder until the pre-receive hook and all other things check out.
It will then be merged into the objects folders and atomically updated files.
However, in the context of BeanHub, this is not good enough. When a Git push happens, we also update many database entries. If the Git operation succeeds but the database transaction fails, our database and the files in the Git repository will be in an inconsistent state. Therefore, we need to find a way to make the Git and database operations all or nothing.
From overlayfs to OCI images
We have plenty of experience working with container images. With a decent understanding of how a container image works, one would know it’s based on an overlayfs filesystem (not 100%, there are some exceptions). When we search for different potential technologies to solve the problems we have above, the idea of a file system that has immutable layers of “delta,” i.e., differences from the previous file structure layer, seems like a perfect match for what we were looking for when it came across our mind.
Why is that? Well, because each time you make a commit or git push, there will be some file changes on top of what you already have. Usually, the changes aren’t that big, provided you don’t push too much history simultaneously. With that in mind, we can capture the changes made in a single git commit or a git push into a layer file. As a layer file is immutable, we can easily keep them in file object storage like AWS S3 with encryption enabled.
We can also easily pull all the layer files into different machines and “replay” them on the machine to reconstruct the whole repository. As long as we cache the base layers, even if a new push is made, the machines with the base layers can quickly pull the new layers, combine them with the previous cached layers, and then have the latest repository file structure.
So far, the layer-based solution solves all the abovementioned problems, but what about atomic? Because each layer presents an atomic unit of changes made to the repository, we can easily commit the layer info into the database with all other entries. In that way, if we fail to commit the layer info, the next time when one reads the repository, it will look at available layers for the repository. As if the layer doesn’t exist in the database, it’s like nothing happens. All problem solved!
What’s an overlayfs, you may ask? It’s a file system that allows you to add an “overlay” as the difference on top of an existing folder. You can think there’s a semi-transparent upper folder on top of a lower folder. Differences can be added in the upper folder, such as modifications, deletions, or additional files. The viewer sees the file structure from the top-down view, so from that perspective, it looks like a merged folder with the content from the lower folder, combining the changes made in the upper folder.

Whatever you change in the overlay filesystem will not affect the underlying filesystem; it will only affect the difference folder. For example, you can create an overlayfs mount like this:
mkdir lower upper work merged
echo "eggs" > lower/file.txt
sudo mount -t overlay overlay -olowerdir=./lower,upperdir=./upper,workdir=./work ./merged
Now, you can see the content of the merged folder:
ls -al merged
And the content looks like this:
total 12
drwxr-xr-x 1 fangpen users 4096 Jun 26 06:48 .
drwxr-xr-x 6 fangpen users 4096 Jun 26 06:49 ..
-rw-r--r-- 1 fangpen users 5 Jun 26 06:50 file.txt
Then, you can change something like this in the upper folder.
echo spam > upper/file.txt
touch upper/new-file
Then you should see the changes you made captured in the upper folder like this:
ls -al upper/
cat upper/file.txt
You will see these
total 12
drwxr-xr-x 2 fangpen users 4096 Jun 26 06:52 .
drwxr-xr-x 6 fangpen users 4096 Jun 26 06:49 ..
-rw-r--r-- 1 fangpen users 5 Jun 26 06:52 file.txt
-rw-r--r-- 1 fangpen users 0 Jun 26 06:52 new-file
spam
If you check the content of lower, you will see nothing changed. To learn more about overlayfs, please read the Linux Kernel document about overlayfs.
At first, we used fuse-overlays (we need to run mount without root) to mount our overlayfs volume with hand-crafted code to untar layer files into folders and then mount.
As we mentioned in our previous blog post, we use Podman to run all the Git operations for security reasons.
Later on, we realized Podman provides an interesting feature: it allows you to mount a container image as a volume.
For example, you can run this to mount the postgres image at /data/postgres in an alpine container like this:
# podman doesn't pull the image for image mount, so we need to pull it manually here
podman pull postgres
podman run --mount=type=image,source=postgres,destination=/data/postgres,rw=true -it alpine
With that, you can look into the postgres Docker image mounting at /data/postgres like this:
ls -al /data/postgres
And you should see content like this:
dr-xr-xr-x 1 root root 4096 Jun 26 05:33 .
drwxr-xr-t 3 root root 4096 Jun 26 05:33 ..
lrwxrwxrwx 1 root root 7 Jun 12 00:00 bin -> usr/bin
drwxr-xr-x 2 root root 4096 Jan 28 21:20 boot
drwxr-xr-x 2 root root 4096 Jun 12 00:00 dev
drwxr-xr-x 2 root root 4096 Jun 13 18:22 docker-entrypoint-initdb.d
drwxr-xr-x 1 root root 4096 Jun 13 18:22 etc
drwxr-xr-x 2 root root 4096 Jan 28 21:20 home
lrwxrwxrwx 1 root root 7 Jun 12 00:00 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Jun 12 00:00 lib64 -> usr/lib64
drwxr-xr-x 2 root root 4096 Jun 12 00:00 media
drwxr-xr-x 2 root root 4096 Jun 12 00:00 mnt
drwxr-xr-x 2 root root 4096 Jun 12 00:00 opt
drwxr-xr-x 2 root root 4096 Jan 28 21:20 proc
drwx------ 1 root root 4096 Jun 13 18:22 root
drwxr-xr-x 1 root root 4096 Jun 13 18:22 run
lrwxrwxrwx 1 root root 8 Jun 12 00:00 sbin -> usr/sbin
drwxr-xr-x 2 root root 4096 Jun 12 00:00 srv
drwxr-xr-x 2 root root 4096 Jan 28 21:20 sys
drwxrwxrwt 2 root root 4096 Jun 12 00:00 tmp
drwxr-xr-x 1 root root 4096 Jun 12 00:00 usr
drwxr-xr-x 1 root root 4096 Jun 12 00:00 var
Yep, that’s exactly the content from the postgres image.
As you see, we are mounting that image with rw=true, which means we can also modify it.
Let’s try it now:
touch /data/postgres/hello
Okay, we just added a new file in the volume mount, but where did the file go? As I said, it’s an overlayfs underlying, so the changes you made don’t really change the content of the docker image. It’s actually captured by the diff folder (or upper). You can find out where’s the upper folder by inspecting the podman container like this
podman inspect 28579e2fa422
You should find out the postgres container image mount looks like this:
{
"Type": "bind",
"Source": "/var/lib/containers/storage/overlay-containers/28579e2fa4220f304a7717fd11e936447082567240a26745aaa9b33f30802770/userdata/overlay/3497122832/merge",
"Destination": "/data/postgres",
"Driver": "",
"Mode": "",
"Options": [
"lowerdir=/var/lib/containers/storage/overlay/dfdc7e8e00d35a9a7b948b699b46ea838d5b58f7352ab02b44c448ef8e233fde/merged",
"upperdir=/var/lib/containers/storage/overlay-containers/28579e2fa4220f304a7717fd11e936447082567240a26745aaa9b33f30802770/userdata/overlay/3497122832/upper",
"workdir=/var/lib/containers/storage/overlay-containers/28579e2fa4220f304a7717fd11e936447082567240a26745aaa9b33f30802770/userdata/overlay/3497122832/work"
],
"RW": true,
"Propagation": "private"
}
To see the content of the upperdir:
ls -al /var/lib/containers/storage/overlay-containers/28579e2fa4220f304a7717fd11e936447082567240a26745aaa9b33f30802770/userdata/overlay/3497122832/upper
Here you go. Exactly like we expected, it captures the changes in the upper folder:
dr-xr-xr-x 2 root root 4096 Jun 25 22:43 .
drwx------ 5 root root 4096 Jun 25 22:33 ..
-rw-r--r-- 1 root root 0 Jun 25 22:43 hello
When we found this, we told ourselves to wait a minute. What we did was the same as how the container image works. Why not just let the Podman do the same thing for us?
Git repository as an OCI Image
As you can see, we can mount a container image on a certain path inside a container and capture the changes made to the mount point. Now we are in business; let’s see an example of creating a Git repository image, mounting it in a container, and making a commit in it.
First, let’s build a container image with only the Git repository as its root file structure with this Dockerfile:
FROM alpine:3.20.1 AS builder
RUN apk add git
RUN mkdir /var/git-repo
WORKDIR /var/git-repo
RUN git init
FROM scratch
COPY --from=builder /var/git-repo .
You can run the following command to build it.
podman build -t git-repo .
After that, let’s mount it in a container.
podman run --mount=type=image,source=git-repo,destination=/data/git,rw=true -it alpine
Next, let’s make a git commit.
apk add git
cd /data/git
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
echo 'hello there' > hello.txt
git add hello.txt
git commit -m "init"
Now, we just made a commit, but what about the changes we made to the repository? Likewise, you can use podman inspect to find the upper folder like this
podman inspect 3712b65f9108
Then you should be able to see the Git repository mount like this:
{
"Type": "bind",
"Source": "/var/lib/containers/storage/overlay-containers/3712b65f910819c886b7b8524d69367923f274c0c7873f84ef22467ace38d18c/userdata/overlay/3150481816/merge",
"Destination": "/data/git",
"Driver": "",
"Mode": "",
"Options": [
"lowerdir=/var/lib/containers/storage/overlay/923f895c46cab0c58039e43a8d7fce5d6f3a354d14f87e86f9fd7aae4e83dac0/merged",
"upperdir=/var/lib/containers/storage/overlay-containers/3712b65f910819c886b7b8524d69367923f274c0c7873f84ef22467ace38d18c/userdata/overlay/3150481816/upper",
"workdir=/var/lib/containers/storage/overlay-containers/3712b65f910819c886b7b8524d69367923f274c0c7873f84ef22467ace38d18c/userdata/overlay/3150481816/work"
],
"RW": true,
"Propagation": "private"
}
Now you know where’s the overlayfs upper layer folder, let’s see what’s in it:
tree -a /var/lib/containers/storage/overlay-containers/3712b65f910819c886b7b8524d69367923f274c0c7873f84ef22467ace38d18c/userdata/overlay/3150481816/upper
There you go! The whole difference made by the git commit command was captured by overlayfs in the upper folder like this:
/var/lib/containers/storage/overlay-containers/3712b65f910819c886b7b8524d69367923f274c0c7873f84ef22467ace38d18c/userdata/overlay/3150481816/upper
├── .git
│ ├── COMMIT_EDITMSG
│ ├── index
│ ├── logs
│ │ ├── HEAD
│ │ └── refs
│ │ └── heads
│ │ └── master
│ ├── objects
│ │ ├── 76
│ │ │ └── b4676f21e49e7bc72588771391647a5eeb79de
│ │ ├── c7
│ │ │ └── c7da3c64e86c3270f2639a1379e67e14891b6a
│ │ └── cd
│ │ └── 3583747ecdced63ccdf4aaa13d1b849aee79bb
│ └── refs
│ └── heads
│ └── master
└── hello.txt
You can pack the .git folder as a tar.gz file as a new layer and upload it to the AWS S3 or other cloud storage.
While it’s overly simplified, basically that’s what we did when you made a git push or a commit.
To automate this process, we built an open-source tool oci-hooks-archive-overlay.
It’s an OCI hook that can archive the upper folder as a tar.gz file after the container is done, as instructed by the annotations.
Now you see how we pack differences made by a git operation into a layer file. You may ask, what about serving the existing repository? To make it possible to serve any Git repository as a container image, we implement the OCI Image repository server ourselves so the podman can pull and mount it.
Forks and Snapshots
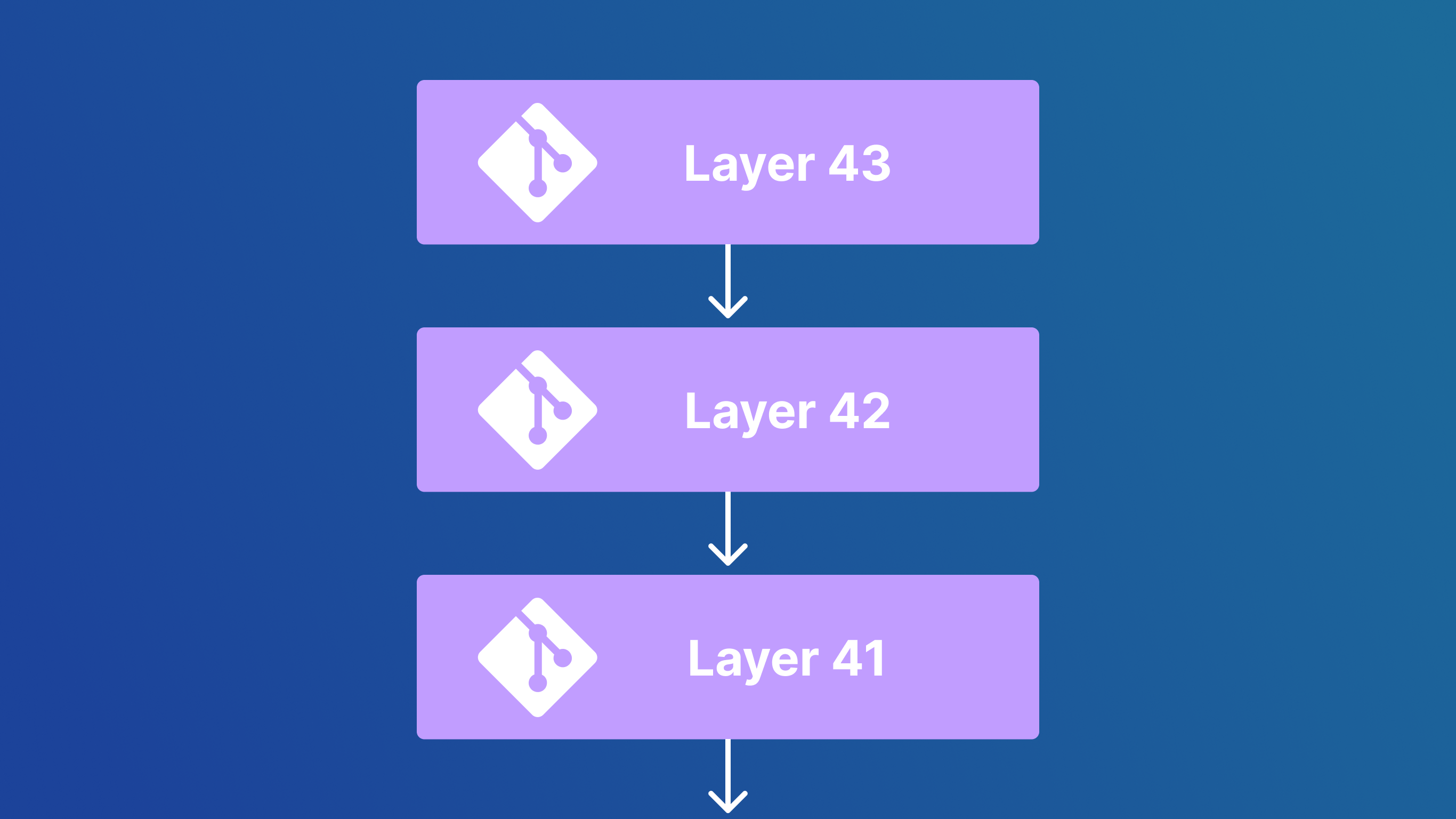
We have learned how BeanHub’s basic Git operations work from a high level. Each Git operation can be represented as a layer pointing to its parent like this:

Some very interesting benefits of this approach include making operations such as forks at almost zero cost. Like for example, for one to fork a repository and make some changes, we only need to create a new layer on top of the existing one like this:

Although we don’t see a strong need for forking a BeanHub repository right now, so the feature is not implemented yet, the layer-based approach allows us to do this beautifully.
While there are many good things about our layer approach to the Git repository, there are also drawbacks. One problem is that if you have enough layers, it will take a long time to pull all the layers and mount them. Each file operation from the latest layer may need to travel down to the very bottom of the older layers. It could also be slow if there are a significant amount of layers. To address the problem, we create snapshots by capturing the full file structure in the repository every N layer so that the number of layers we need to mount will stay manageable.

Final thought
We have learned a lot from building BeanHub. The container image layer-based Git repository system is one of the most challenging systems we’ve built with a very interesting approach. We hope you also learn something from our article. This series of articles on how BeanHub works is inspired by Tailscale’s blog posts, which introduces how their VPN system works. We admire that they beautifully explain how their system works in detail.
Writing articles like these is very time-consuming. If you found this article interesting, please share it to help motivate us to write more. Feedback is also welcome. You can reach out to us at support@beanhub.io if you are interested in learning about the technical aspects of BeanHub. We might be able to write some articles about them. Finally, thank you for your time reading :)
